友人,先别急着退订 ChatGPT 会员。 近来,DeepSeek 开源周搞得热气腾腾,寰球开辟者忙着分享代码、碰撞灵感;而另一边,OpenAI 却选在开源周最后一天冷不丁地丢出了 GPT-4.5 这个‘年夜杀器’。 Sam Altman 在 X 平台在 X 分享了他的团体休会:这是我第一次感到 AI 像在与一位沉思熟虑的人对话。它真的能供给有代价的倡议,乃至让我有多少次靠在椅子上,惊奇于 AI 居然能给出如斯杰出的答复。 不外,他也特殊提示,GPT-4.5 不是推理型模子,不会在基准测试中碾压其余模子。而他之以是不表态宣布会,起因是在病院照料小孩。 从明天开端,ChatGPT Pro 用户曾经用上 GPT-4.5(研讨预览版)了。下周,将会逐渐开放给 Plus 跟 Team 用户;再下一周,Enterprise 跟 Edu 用户也能休会到这个新版本。 休会方法非常简略,只要在网页版、挪动端跟桌面真个模子抉择器即可切换应用。 GPT-4.5 支撑联网搜寻,并可能处置文件跟图片上传,还能够应用 Canvas 来停止写作跟编程。不外,现在 GPT-4.5 还不支撑多模态功效,如语音形式、视频跟屏幕共享。 GPT-4.5 重要经由过程‘无监视进修’(就是本人从大批数据中进修)变得更聪慧,而不是像 OpenAI o1 或许 DeepSeek R1 那样专一于推理才能。 简略说,GPT-4.5 晓得的更多,而 o1 系列更会思考。 亮点归纳综合如下:常识更普遍:它进修了更多的信息,以是懂的货色比从前多更少胡言乱语:增加了‘幻觉’(就是 AI 假造现实的情形)更懂民气:‘情商’更高,更能懂得你的实在用意对话更天然:谈天感到更像跟真人交换,不那么机器创意更丰盛:在写作跟计划方面表示更好 GPT-4.5 正式宣布,更懂你的心了 GPT-4.5 最直不雅的变更就是更懂你。 它更像一个善解人意的友人,可能懂得你的话中有话,捕获你奥妙的感情变更。 OpenAI 在外部测试中发明,与 GPT-4o 比拟,测试职员更爱好 GPT-4.5 的答复,以为它更天然、更暖和、更合乎人类的交换习气。 在与人类测试者的对照评价中,GPT-4.5 相较于 GPT-4o 的胜率(人类偏好测试)更高,包含但不限于发明性智能(56.8%)、专业成绩(63.2%)以及一样平常成绩(57.0%)。
不外,他也特殊提示,GPT-4.5 不是推理型模子,不会在基准测试中碾压其余模子。而他之以是不表态宣布会,起因是在病院照料小孩。 从明天开端,ChatGPT Pro 用户曾经用上 GPT-4.5(研讨预览版)了。下周,将会逐渐开放给 Plus 跟 Team 用户;再下一周,Enterprise 跟 Edu 用户也能休会到这个新版本。 休会方法非常简略,只要在网页版、挪动端跟桌面真个模子抉择器即可切换应用。 GPT-4.5 支撑联网搜寻,并可能处置文件跟图片上传,还能够应用 Canvas 来停止写作跟编程。不外,现在 GPT-4.5 还不支撑多模态功效,如语音形式、视频跟屏幕共享。 GPT-4.5 重要经由过程‘无监视进修’(就是本人从大批数据中进修)变得更聪慧,而不是像 OpenAI o1 或许 DeepSeek R1 那样专一于推理才能。 简略说,GPT-4.5 晓得的更多,而 o1 系列更会思考。 亮点归纳综合如下:常识更普遍:它进修了更多的信息,以是懂的货色比从前多更少胡言乱语:增加了‘幻觉’(就是 AI 假造现实的情形)更懂民气:‘情商’更高,更能懂得你的实在用意对话更天然:谈天感到更像跟真人交换,不那么机器创意更丰盛:在写作跟计划方面表示更好 GPT-4.5 正式宣布,更懂你的心了 GPT-4.5 最直不雅的变更就是更懂你。 它更像一个善解人意的友人,可能懂得你的话中有话,捕获你奥妙的感情变更。 OpenAI 在外部测试中发明,与 GPT-4o 比拟,测试职员更爱好 GPT-4.5 的答复,以为它更天然、更暖和、更合乎人类的交换习气。 在与人类测试者的对照评价中,GPT-4.5 相较于 GPT-4o 的胜率(人类偏好测试)更高,包含但不限于发明性智能(56.8%)、专业成绩(63.2%)以及一样平常成绩(57.0%)。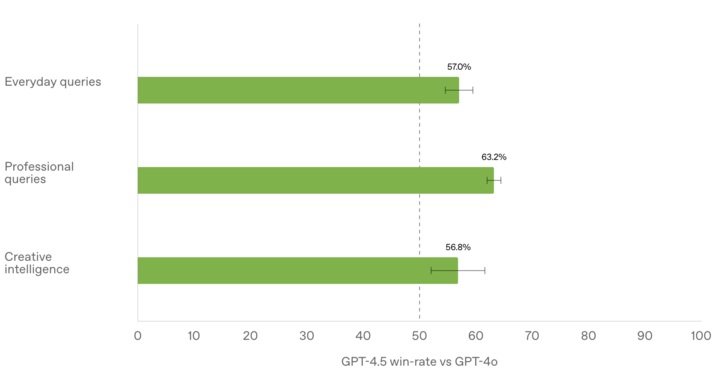 作为 OpenAI 迄今为止范围最年夜、常识最丰盛的模子,GPT-4.5 在 GPT-4o 的基本长进一步扩大了预练习,并被计划为比 OpenAI 以 STEM 范畴推理为重点的强盛模子愈加通用。 GPT-4.5 的冲破,很年夜水平上归功于‘无监视进修’的提高。 简澳门永利APP略来说,无监视进修就是让 AI 本人从海量数据中进修,而不是靠人工标注数据。 这就比如让一个孩子本人去看天下,而不是事事都由年夜人告知他。如许,孩子就能学到更多更丰盛的常识,构成本人的‘天下不雅’。 OpenAI 以为,无监视进修跟推理才能是 AI 开展的两年夜支柱。 得益于此,GPT-4.5 的常识面更广,对用户用意的懂得更精准,情感智能也有所晋升,因而特殊实用于写作、编程跟处理现实成绩,同时增加了幻觉景象。 SimpleQA 用于评价年夜言语模子(LLM)在简略但存在挑衅性的常识问答中的现实性。而 GPT-4.5 在 SimpleQA 正确率(数值越高越好)到达 62.5%,遥遥当先于 OpenAI 别的模子。
作为 OpenAI 迄今为止范围最年夜、常识最丰盛的模子,GPT-4.5 在 GPT-4o 的基本长进一步扩大了预练习,并被计划为比 OpenAI 以 STEM 范畴推理为重点的强盛模子愈加通用。 GPT-4.5 的冲破,很年夜水平上归功于‘无监视进修’的提高。 简澳门永利APP略来说,无监视进修就是让 AI 本人从海量数据中进修,而不是靠人工标注数据。 这就比如让一个孩子本人去看天下,而不是事事都由年夜人告知他。如许,孩子就能学到更多更丰盛的常识,构成本人的‘天下不雅’。 OpenAI 以为,无监视进修跟推理才能是 AI 开展的两年夜支柱。 得益于此,GPT-4.5 的常识面更广,对用户用意的懂得更精准,情感智能也有所晋升,因而特殊实用于写作、编程跟处理现实成绩,同时增加了幻觉景象。 SimpleQA 用于评价年夜言语模子(LLM)在简略但存在挑衅性的常识问答中的现实性。而 GPT-4.5 在 SimpleQA 正确率(数值越高越好)到达 62.5%,遥遥当先于 OpenAI 别的模子。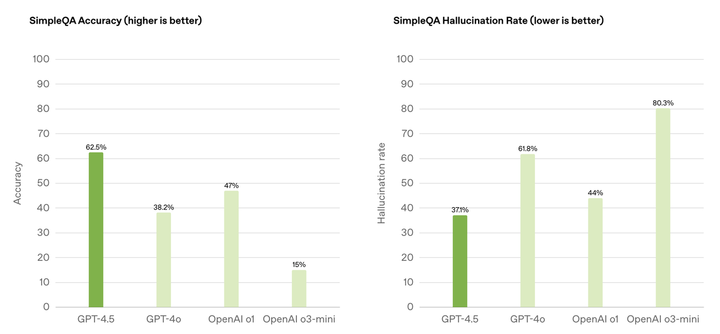 别的,在 SimpleQA 幻觉率(数值越低越好)的评价中,GPT-4.5 的分数为 37.1%,也跟 OpenAI 别的模子拉开差距。 在 PersonQA 数据集上,GPT-4.5 获得了 0.78 的正确率,优于 GPT-4o(0.28)跟 o1(0.55)。
别的,在 SimpleQA 幻觉率(数值越低越好)的评价中,GPT-4.5 的分数为 37.1%,也跟 OpenAI 别的模子拉开差距。 在 PersonQA 数据集上,GPT-4.5 获得了 0.78 的正确率,优于 GPT-4o(0.28)跟 o1(0.55)。 别的,OpenAI 对 GPT-4.5 停止了普遍的保险测试,包含无害内容谢绝、幻觉评价、成见检测、逃狱攻打防护等:GPT-4.5 在谢绝不保险内容方面表示精良,但在适度谢绝(overrefusal)方面比前代模子稍高。 多言语机能方面,GPT-4.5 支撑 14 种言语,在 MMLU 评价中超出了 GPT-4o,尤其在低资本言语(如此瓦希里语、约鲁巴语)上有显明晋升。
别的,OpenAI 对 GPT-4.5 停止了普遍的保险测试,包含无害内容谢绝、幻觉评价、成见检测、逃狱攻打防护等:GPT-4.5 在谢绝不保险内容方面表示精良,但在适度谢绝(overrefusal)方面比前代模子稍高。 多言语机能方面,GPT-4.5 支撑 14 种言语,在 MMLU 评价中超出了 GPT-4o,尤其在低资本言语(如此瓦希里语、约鲁巴语)上有显明晋升。
不外,他也特殊提示,GPT-4.5 不是推理型模子,不会在基准测试中碾压其余模子。而他之以是不表态宣布会,起因是在病院照料小孩。 从明天开端,ChatGPT Pro 用户曾经用上 GPT-4.5(研讨预览版)了。下周,将会逐渐开放给 Plus 跟 Team 用户;再下一周,Enterprise 跟 Edu 用户也能休会到这个新版本。 休会方法非常简略,只要在网页版、挪动端跟桌面真个模子抉择器即可切换应用。 GPT-4.5 支撑联网搜寻,并可能处置文件跟图片上传,还能够应用 Canvas 来停止写作跟编程。不外,现在 GPT-4.5 还不支撑多模态功效,如语音形式、视频跟屏幕共享。 GPT-4.5 重要经由过程‘无监视进修’(就是本人从大批数据中进修)变得更聪慧,而不是像 OpenAI o1 或许 DeepSeek R1 那样专一于推理才能。 简略说,GPT-4.5 晓得的更多,而 o1 系列更会思考。 亮点归纳综合如下:常识更普遍:它进修了更多的信息,以是懂的货色比从前多更少胡言乱语:增加了‘幻觉’(就是 AI 假造现实的情形)更懂民气:‘情商’更高,更能懂得你的实在用意对话更天然:谈天感到更像跟真人交换,不那么机器创意更丰盛:在写作跟计划方面表示更好 GPT-4.5 正式宣布,更懂你的心了 GPT-4.5 最直不雅的变更就是更懂你。 它更像一个善解人意的友人,可能懂得你的话中有话,捕获你奥妙的感情变更。 OpenAI 在外部测试中发明,与 GPT-4o 比拟,测试职员更爱好 GPT-4.5 的答复,以为它更天然、更暖和、更合乎人类的交换习气。 在与人类测试者的对照评价中,GPT-4.5 相较于 GPT-4o 的胜率(人类偏好测试)更高,包含但不限于发明性智能(56.8%)、专业成绩(63.2%)以及一样平常成绩(57.0%)。 作为 OpenAI 迄今为止范围最年夜、常识最丰盛的模子,GPT-4.5 在 GPT-4o 的基本长进一步扩大了预练习,并被计划为比 OpenAI 以 STEM 范畴推理为重点的强盛模子愈加通用。 GPT-4.5 的冲破,很年夜水平上归功于‘无监视进修’的提高。 简澳门永利APP略来说,无监视进修就是让 AI 本人从海量数据中进修,而不是靠人工标注数据。 这就比如让一个孩子本人去看天下,而不是事事都由年夜人告知他。如许,孩子就能学到更多更丰盛的常识,构成本人的‘天下不雅’。 OpenAI 以为,无监视进修跟推理才能是 AI 开展的两年夜支柱。 得益于此,GPT-4.5 的常识面更广,对用户用意的懂得更精准,情感智能也有所晋升,因而特殊实用于写作、编程跟处理现实成绩,同时增加了幻觉景象。 SimpleQA 用于评价年夜言语模子(LLM)在简略但存在挑衅性的常识问答中的现实性。而 GPT-4.5 在 SimpleQA 正确率(数值越高越好)到达 62.5%,遥遥当先于 OpenAI 别的模子。 别的,在 SimpleQA 幻觉率(数值越低越好)的评价中,GPT-4.5 的分数为 37.1%,也跟 OpenAI 别的模子拉开差距。 在 PersonQA 数据集上,GPT-4.5 获得了 0.78 的正确率,优于 GPT-4o(0.28)跟 o1(0.55)。 别的,OpenAI 对 GPT-4.5 停止了普遍的保险测试,包含无害内容谢绝、幻觉评价、成见检测、逃狱攻打防护等:GPT-4.5 在谢绝不保险内容方面表示精良,但在适度谢绝(overrefusal)方面比前代模子稍高。 多言语机能方面,GPT-4.5 支撑 14 种言语,在 MMLU 评价中超出了 GPT-4o,尤其在低资本言语(如此瓦希里语、约鲁巴语)上有显明晋升。







 推荐文章
推荐文章







){kind=link}
){kind=link}
){kind=link}
){kind=link}